Jenis Multiple Processor Organization
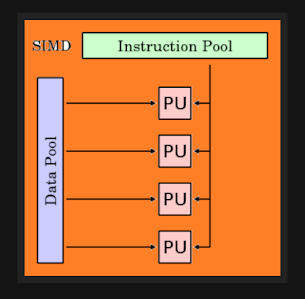
SIMD (Single Instruction Multiple Data)
Yang merupakan singkatan dari Single Instruction, Multiple Data. SIMD menggunakan banyak processor dengan instruksi yang sama, namun setiap processor mengolah data yang berbeda. Sebagai contoh kita ingin mencari angka 27 pada deretan angka yang terdiri dari 100 angka, dan kita menggunakan 5 processor. Pada setiap processor kita menggunakan algoritma atau perintah yang sama, namun data yang diproses berbeda. Misalnya processor 1 mengolah data dari deretan / urutan pertama hingga urutan ke 20, processor 2 mengolah data dari urutan 21 sampai urutan 40, begitu pun untuk processor-processor yang lain. Beberapa contoh komputer yang menggunakan model SIMD adalah ILLIAC IV, MasPar, Cray X-MP, Cray Y-MP, Thingking Machine CM-2 dan Cell Processor (GPU).Kelas komputer paralel dalam taksonomi Flynn . Ini menggambarkan komputer dengan beberapa elemen pemrosesan yang melakukan operasi yang sama pada beberapa titik data secara bersamaan. Dengan demikian, mesin tersebut memanfaatkan data tingkat paralelisme . SIMD ini terutama berlaku untuk tugas umum seperti menyesuaikan kontras dalam citra digital atau menyesuaikan volume audio digital . Paling modern CPU desain termasuk instruksi SIMD dalam rangka meningkatkan kinerja multimedia digunakan.
Keuntungan SIMD antara lain sebuah aplikasi yang dapat mengambil keuntungan dari SIMD adalah salah satu di mana nilai yang sama sedang ditambahkan ke (atau dikurangkan dari) sejumlah besar titik data, operasi umum di banyak multimedia aplikasi. Salah satu contoh akan mengubah kecerahan gambar. Setiap pixel dari suatu gambar terdiri dari tiga nilai untuk kecerahan warna merah (R), hijau (G) dan biru (B) bagian warna. Untuk mengubah kecerahan, nilai-nilai R, G dan B yang dibaca dari memori, nilai yang ditambahkan dengan (atau dikurangi dari) mereka, dan nilai-nilai yang dihasilkan ditulis kembali ke memori.
Dengan prosesor SIMD ada dua perbaikan proses ini. Untuk satu data dipahami dalam bentuk balok, dan sejumlah nilai-nilai dapat dimuat sekaligus. Alih-alih serangkaian instruksi mengatakan “mendapatkan pixel ini, sekarang mendapatkan pixel berikutnya”, prosesor SIMD akan memiliki instruksi tunggal yang efektif mengatakan “mendapatkan n piksel” (dimana n adalah angka yang bervariasi dari desain untuk desain). Untuk berbagai alasan, ini bisa memakan waktu lebih sedikit daripada “mendapatkan” setiap pixel secara individual, seperti desain CPU tradisional.
Keuntungan lain adalah bahwa sistem SIMD biasanya hanya menyertakan instruksi yang dapat diterapkan pada semua data dalam satu operasi. Dengan kata lain, jika sistem SIMD bekerja dengan memuat delapan titik data sekaligus, add operasi yang diterapkan pada data akan terjadi pada semua delapan nilai pada waktu yang sama. Meskipun sama berlaku untuk setiap desain prosesor super-skalar, tingkat paralelisme dalam sistem SIMD biasanya jauh lebih tinggi.
Kekurangannya adalah : Tidak semua algoritma dapat vectorized. Misalnya, tugas aliran-kontrol-berat seperti kode parsing tidak akan mendapat manfaat dari SIMD. Ia juga memiliki file-file register besar yang meningkatkan konsumsi daya dan area chip. Saat ini, menerapkan algoritma dengan instruksi SIMD biasanya membutuhkan tenaga manusia, sebagian besar kompiler tidak menghasilkan instruksi SIMD dari khas C Program, misalnya. vektorisasi dalam kompiler merupakan daerah aktif penelitian ilmu komputer. (Bandingkan pengolahan vektor .)
Pemrograman dengan khusus SIMD set instruksi dapat melibatkan berbagai tantangan tingkat rendah.
SSE (Streaming SIMD Ekstensi) memiliki pembatasan data alignment , programmer akrab dengan arsitektur x86 mungkin tidak mengharapkan ini. Mengumpulkan data ke dalam register SIMD dan hamburan itu ke lokasi tujuan yang benar adalah rumit dan dapat menjadi tidak efisien.Instruksi tertentu seperti rotasi atau penambahan tiga operan tidak tersedia dalam beberapa set instruksi SIMD.
Set instruksi adalah arsitektur-spesifik: prosesor lama dan prosesor non-x86 kekurangan SSE seluruhnya, misalnya, jadi programmer harus menyediakan implementasi non-Vectorized (atau implementasi vectorized berbeda) untuk mereka. Awal MMX set instruksi berbagi register file dengan tumpukan floating-point, yang menyebabkan inefisiensi saat pencampuran kode floating-point dan MMX. Namun, SSE2 mengoreksi ini. SIMD dibagi menjadi beberapa bentuk lagi yaitu :
1. Exclusive-Read, Exclusive-Write (EREW) SM SIMD
2. Concurent-Read, Exclusive-Write (CREW) SM SIMD
3. Exclusive-Read, Concurrent-Write (ERCW) SM SIMD
4. Concurrent-Read, Concurrent-Write (CRCW) SM SIMD


Komentar
Posting Komentar